
Imagine a nation whose government is elected regularly, but not based on regular elections. Instead, officials routinely visit pubs, where they monitor which politicians are most often mentioned by clients discussing current events. Based on this evidence, the officials build a ranking of politicians, and this ranking is used to assign positions in the government and other public bodies. For different reasons, officials have found creative and clever ways to aggregate the mentions. This has resulted in a proliferation of metrics, sometimes obscure, often in disagreement between them. But in the end, they are still counting the names of politicians mentioned in casual chatting. With the consequence that pub goers are pestered by politicians asking them to include their name in possibly vaguely related statements, and by pub owners requiring those who want to get into the pub to occasionally name a few politicians they are sympathetic with. This is the status of bibliometry today.
![]() is different from common bibliometric indicators because it entirely avoids relying on clues – citations – that were never meant to serve as a measure of quality. The only foundation for our metric is the researchers’ explicit (albeit confidential) assessment of scientific journals’ standing.
is different from common bibliometric indicators because it entirely avoids relying on clues – citations – that were never meant to serve as a measure of quality. The only foundation for our metric is the researchers’ explicit (albeit confidential) assessment of scientific journals’ standing.

In particular, we ask researchers to rank journals they know well.
We then aggregate their rankings into a global one that reflects each researchers’s assessment over his or her own area of expertise.
Clearly, we do not expect researchers to necessarily share the same opinion on journals’ standings. The spirit of our aggregation method is to minimize disagreement with individual rankings.
The smart poll
At the core of our project is a survey restricted to authors of publications in scientific journals. It is smart in the sense that it is tailored around each respondent. That is, each participant is first and foremost asked to rank a short list of journals he or she published in during the last years, in a bottom-up approach.
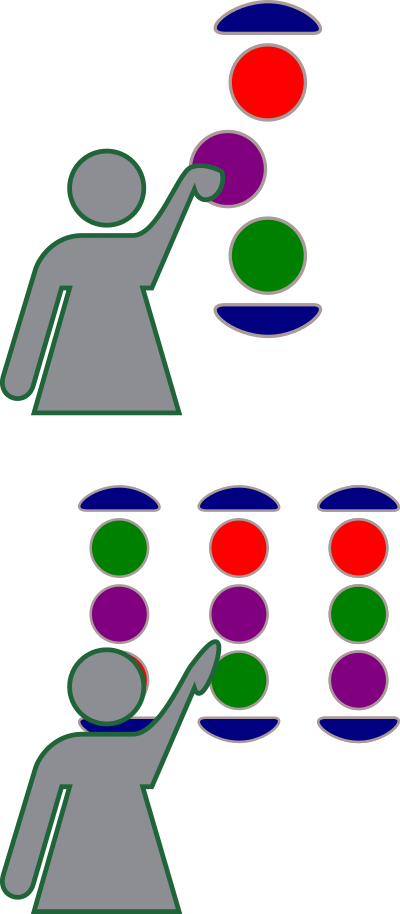
Then, a few other rankings of the same journals are provided, and the researcher is asked to indicate which of these better capture the quality of research published on each journal, in a top-down approach.
Finally, we ask the researcher to compare journals in the first list to a few others closely related to those over which they published. Our measure of relatedness is based on a network of journals where any two journals are considered closer the more authors they have in common.
Expected impact
The main outcome of our project will be the creation of ![]() , the new journals ranking based on the bottom-up approach – aggregating the assessments of individual researchers, independent of citation counts.
, the new journals ranking based on the bottom-up approach – aggregating the assessments of individual researchers, independent of citation counts.
However, our analysis will also provide insights over which of the various already existing bibliometric indicators better reflect researchers’ opinions.
This will be done both by exploiting the top-down part of the smart pool, and by measuring the degree of agreement of ![]() with existing indicators.
with existing indicators.
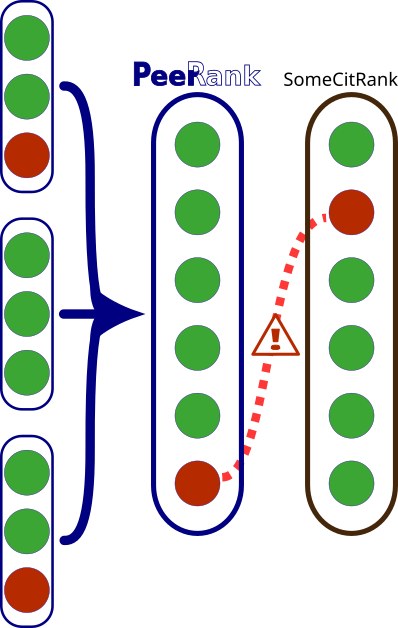
Beyond providing a new metric that reflects the views of researchers, our work will help mitigate, and in some cases identify, the manipulation of metrics via artificial citations pumping. In particular, while some level of disagreement between rankings is natural, any journals with exceptionally higher standings in citation-based rankings as compared to ![]() will be an immediate red flag. This possibly includes some predatory journals that are better at setting up citation exchange schemes than actually increasing their reputation.
will be an immediate red flag. This possibly includes some predatory journals that are better at setting up citation exchange schemes than actually increasing their reputation.
Scientific output

In terms of scientific results, the first research question we will be able to address is to what extent researchers (do not) agree in their evaluation of research outlets. While we do expect researchers to occasionally disagree, we also think that the relative opinion of different researchers on a given set of journal typically exhibit very strong positive correlation, a conjecture that we will be able to test explicitly.
Secondly, since the bottom-up part of our smart poll includes a few journals on which a researcher did not publish, we will be able to measure any systematic bias in favor of one’s own publications. In a similar vein, we can combine our results with public data to look for bias towards a journal the respondent is in the editorial board of. More in general, we will be able to map, in a data-driven way, sets of journals/researchers which form coalitions or, vice-versa, identify possible fields of research which feature strong fissures in their evaluations.
The literature on scientific production (and the scientific community in general) is looking with increasing concern at the phenomenon of predatory journals. Since ![]() will help identify them – by providing a measure which is less prone to manipulation than citations-based measures – we will also have new tools to understand the phenomenon, including understanding which authors tend to choose these research outlets. More in general, we will provide a much needed measure of reputation to analyze the extremely heterogeneous world of open access journals.
will help identify them – by providing a measure which is less prone to manipulation than citations-based measures – we will also have new tools to understand the phenomenon, including understanding which authors tend to choose these research outlets. More in general, we will provide a much needed measure of reputation to analyze the extremely heterogeneous world of open access journals.
Last but not least, the development and fine tuning of the aggregation algorithm will inform on the pros and cons of different approaches that can be used to aggregate individual rankings over a given set of options. While many such algorithms exist (some of them, such as the Schulze method, being regularly employed in elections around the world), our application features the specific challenge of a very long menu of options (journals), of which each voter can express preferences on only a short submenu. Our algorithm will need to be at the same time transparent, deterministic, computationally feasible and robust to manipulation.
More questions?
Check out our FAQs…
…or contact us at info AT peerrank DOT org!